The End of your Three-Week Data Request
The Waiting Room
Every data team has the same dirty secret: a graveyard of Slack messages that start with "quick question about our numbers."

You know how this goes. Marketing asks which campaigns actually drive revenue. Three weeks later, after seventeen back-and-forths about defining "revenue" and four meetings about attribution windows, they get a CSV that's already out of date. By the time the analysis arrives, the campaign budget has been spent, the quarter is over, and everyone's moved on to the next fire.
The modern data stack was supposed to fix this. We got warehouses that could query petabytes in seconds. We got dbt to transform everything. We got reverse ETL, metrics layers, semantic models, observability tools. We got everything except the thing people actually wanted: answers to their questions when they need them.
Meanwhile, your data team is drowning. Not because they're slow or incompetent, but because the entire system is broken. They're translating business questions into SQL, explaining why the numbers don't match, teaching people how to use yet another BI tool that promises "self-serve analytics" but delivers another dashboard graveyard.
Today, we're launching Ana—TextQL's agentic data scientist. Ana doesn't fix your data team's workflow. She replaces it.
The Spark
Six months ago, we were watching our customers struggle with a paradox. They had all this infrastructure—Snowflake billing them $500K a year, a team of eight analysts, enough dashboards to wallpaper Manhattan. But when the CEO asked "why did revenue dip last week?", it still took three days to get an answer.
We started with the obvious approach: make SQL easier to write. Another text-to-SQL wrapper around GPT-4. Another chatbot that writes queries nobody trusts. We built it, tested it, watched it fail in exactly the ways everyone predicted. The SQL was mostly right but occasionally catastrophically wrong. The business context was missing. The analysis was shallow.
Then we noticed something. The best data analysts don't just write SQL. They're detectives. They get a vague question, form hypotheses, pull data, realize they need different data, pivot their approach, run statistical tests, create visualizations, and iterate until they find the real story. The SQL is maybe 20% of the work.
That's when we realized: we weren't building a SQL writer. We were building an analyst. An agent that can automate the entire data analytics life cycle while humans do the strategic thinking.
How Ana Actually Works
Ana connects directly to your data warehouse—Snowflake, BigQuery, Databricks, Redshift, whatever you're running. But here's what nobody else will tell you: every other AI data tool assumes you have one clean schema and that's it. They're built for the platonic ideal of a data stack that exists nowhere outside of dbt's marketing materials.
We built Ana differently because your data doesn't live in one place. It's scattered across warehouses, semantic layers, BI tools, documentation systems, and that one Google Sheet your CFO insists on using. Ana is the only system built from day one to handle this reality.
Got a Cube or Looker semantic layer? Ana queries it directly, understanding your pre-built metrics and definitions. Found the answer in an existing Tableau dashboard? Ana can either pull the underlying SQL or grab the data sources directly. Your business context lives in Confluence? MCP support means Ana reads it. Data catalog in Secoda? She's already browsing it.
This was stupidly hard to build. Every data tool has its own API, its own permissions model, its own way of representing the same concepts. We spent six months just on the abstraction layer that lets Ana understand that revenue in your semantic layer, total_revenue_usd in your warehouse, and Monthly Revenue in your CEO's dashboard are all the same thing.
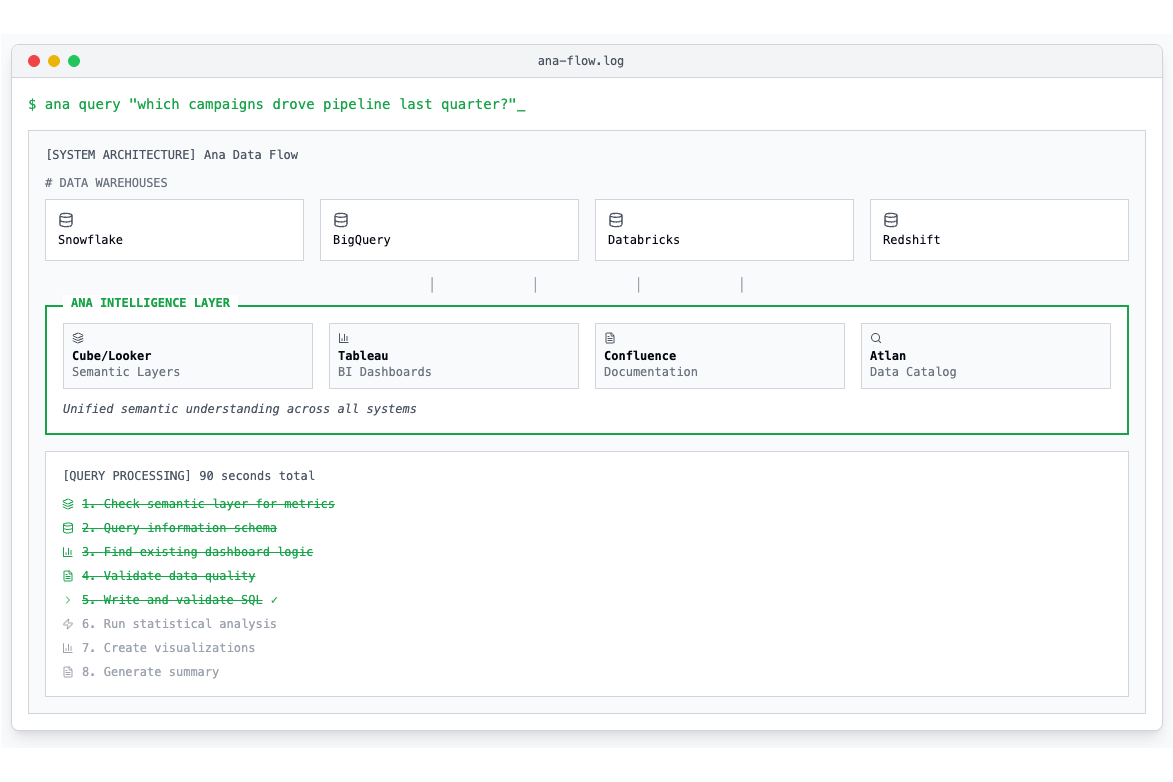
When someone asks "which campaigns drove pipeline last quarter?", Ana doesn't just write one SQL query. She:
- Checks your semantic layer first—maybe you already defined pipeline attribution there
- Queries the information schema to identify relevant tables if needed
- Looks for existing dashboard logic she can reuse (why rebuild what your BI team already validated?)
- Checks for data quality issues using your catalog's documentation
- Writes and validates the SQL query
- Runs statistical analysis in Python (is that 20% lift actually significant or just noise?)
- Creates visualizations that actually answer the question
- Writes a summary explaining what she found and what it means
The entire process takes about ninety seconds. The same request to a human analyst takes three days if you're lucky—partly because they're busy, but mostly because they have to navigate this same maze of systems manually.
Every other "AI analyst" makes you rebuild your entire data stack around their opinion. Ana works with the mess you already have.
The Tactical Reality
Here's what we're not going to tell you: Ana replaces your entire data team. That's VC pitch deck fantasy.
Ana handles the reactive analysis—the constant stream of "quick questions" that consume 70% of your analysts' time. The deep strategic work, the data modeling, the complex investigations that require business context a model can't access—that's still human territory.
But here's what actually happens when you deploy Ana:
Your data team stops being a bottleneck. They stop answering the same revenue attribution question seventeen times a month. They stop building dashboards nobody looks at. They start doing the work they actually want to do—building data products, designing experiments, solving hard problems.
Your business users stop waiting. That campaign optimization that used to happen quarterly? Now it happens weekly. That sales territory analysis that took a month? Now it takes an afternoon. Not because Ana is magic, but because she's available.
We've seen companies cut their average time-to-insight from 16 days to 4 hours. Not on simple queries—on real business questions with multiple data sources and complex logic.
The Security Theatre
Every enterprise AI product promises "bank-level security" while shipping your data to OpenAI's servers. We built Ana differently because we had to. Our early customers included a defense contractor and two financial services firms who would have literally laughed us out of the room if we'd suggested shipping their data to anyone's API.
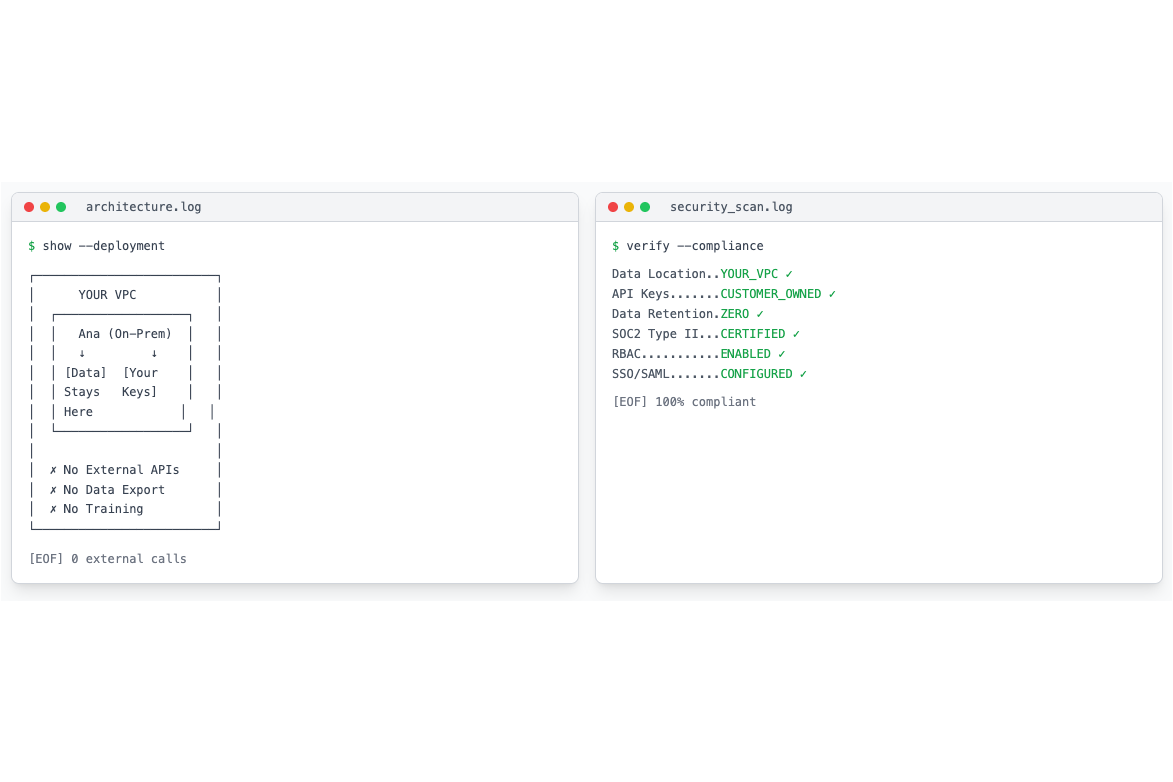
Ana runs in your VPC. Your data never leaves your network. The LLM calls happen through Azure OpenAI or AWS Bedrock with your own keys. We don't see your data. We don't store your queries. We definitely don't train on your revenue numbers.
Role-based access control means your sales team can't accidentally query HR data. SOC2 Type II certified because that's table stakes. SAML SSO through Okta or Microsoft Entra because your IT team already hates managing passwords.
Why This Matters Now
The timing isn't accidental. Three things had to happen for Ana to be possible:
- LLMs got good enough at code generation. Not perfect, but Claude 4 represented a step function improvement on an agent’s ability to explore environment as complex as 10,000 table data warehouses w/o documentation, and make sense of it. But good enough that with the right scaffolding, they can write reliable SQL and Python.
- The modern data stack stabilized. Five years ago, every company had a different setup. Now it's Snowflake or BigQuery, dbt for transformation, maybe Fivetran for ingestion. The patterns are predictable enough to build against.
- Companies realized self-serve analytics failed. That dream of every employee writing their own SQL? Dead. The average marketer doesn't want to learn SQL any more than the average analyst wants to learn Facebook Ads Manager.
What's Next
We're shipping Ana with the features that matter today: warehouse connectivity, API integrations for real-time data, Python notebooks for complex analysis. But we're building toward something bigger.
Imagine Ana not just answering questions but asking them. "Hey, your CAC just jumped 40% in the Northeast region—want me to dig into why?" Or connecting to your Slack and CRM, understanding the full context of your business, not just what's in the warehouse.
We're exploring agentic workflows where Ana handles entire analysis projects. Not just "what happened?" but "what should we do about it?" with scenario modeling, forecasting, and recommendations.
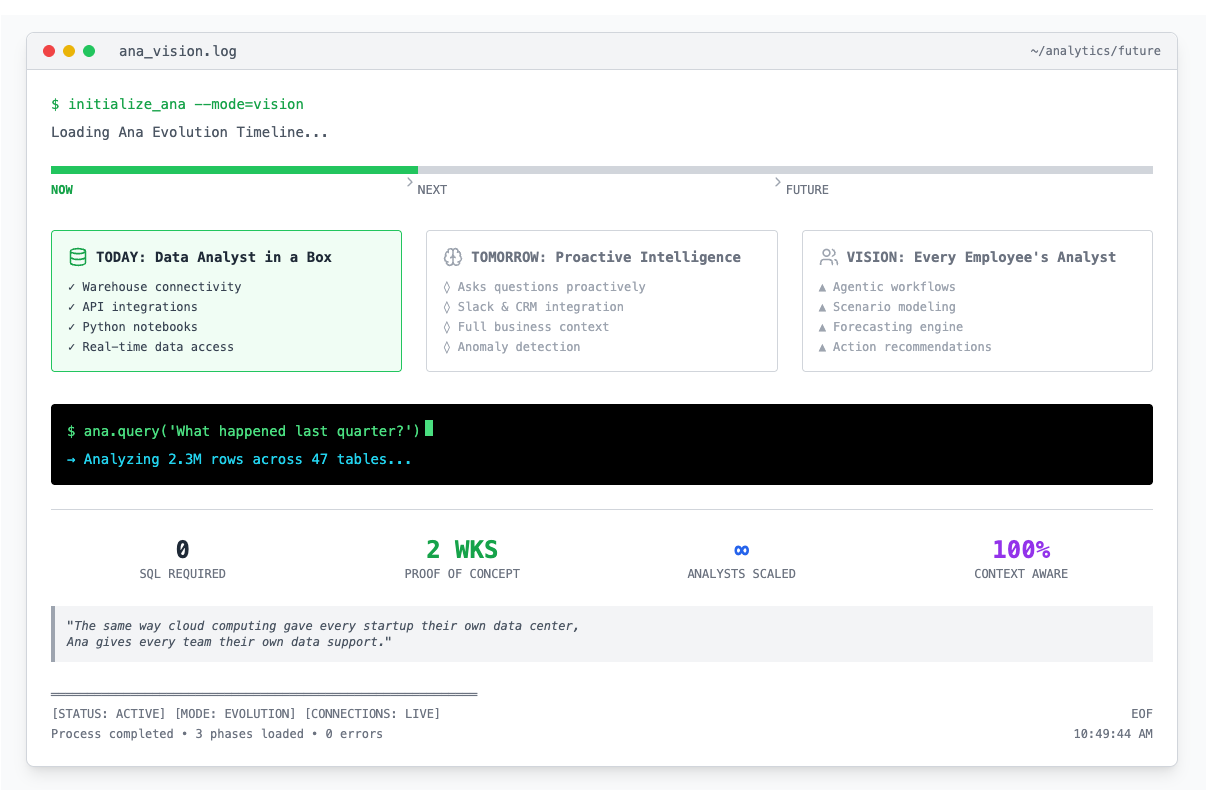
The end state isn't replacing analysts. It's giving every employee their own analyst. The same way cloud computing gave every startup their own data center, Ana gives every team their own data support.
Getting Started
Here's the part where I'm supposed to tell you about our free trial and how you can get started in minutes. But Ana isn't a self-serve product you can spin up with a credit card. She needs to understand your business, your data model, your specific context.
We do two-week proof of concepts. We'll connect to your warehouse, configure Ana for your schema, and let your team hammer her with real questions. Either she delivers value immediately or she doesn't. No six-month implementations. No consulting fees. No "it'll work better after we tune it for another quarter."
The companies that win in the next decade will be the ones that can actually use their data, not just store it. The question is whether you want to keep hiring analysts to write SQL, or whether you want to skip straight to getting answers.
Request a demo at textql.com/request-demo.
We'll have you analyzing your production data before the call ends. That's not marketing. We literally do it on every demo because it's the only way to show this actually works.
P.S. For the technical readers wondering about the implementation details: Ana uses a mixture of claude-4-sonnet for query planning and code generation, with a proprietary validation layer that catches the hallucinations before they hit your warehouse. The Python analysis runs in isolated containers with numpy, pandas, and scipy. The whole thing costs us about $0.40 per query to run, which means we can offer unlimited queries at prices that would make your analysts laugh. The margin math actually works, unlike certain coding assistants.