
TLDR: Enterprise data analysis requires agents to query and store datasets far too large for context windows. Sandcastles are execution environments purpose-built for this: isolated containers with high-performance data access via Apache Arrow streaming, unified interfaces across heterogeneous sources (warehouses, databases, APIs), and enterprise RBAC baked in.
Every AI agent that works with data needs somewhere to run code. The industry calls these environments sandboxes – isolated containers where an agent can execute Python, query databases, and manipulate files without risk to production systems. As agents take on more complex analytical work, sandboxes have become essential infrastructure.
But most sandboxes are general-purpose. They're built to run AI generated code, not to wrestle with the specific challenges of enterprise data: dozens of sources speaking different dialects, datasets too large for context windows, and security requirements that make compliance teams nervous. We've spent the past two years building something more specialized. We call it the Sandcastle, a sandbox designed from the ground up for analytical workloads. This post walks through what that means architecturally and how we got here.
What are sandboxes?
At their core, sandboxes are isolated execution environments where code can run without risk to the host system. Think of them as controlled rooms where an agent can experiment freely by writing code, manipulating files, running computations without any possibility of affecting production systems or leaking sensitive data.
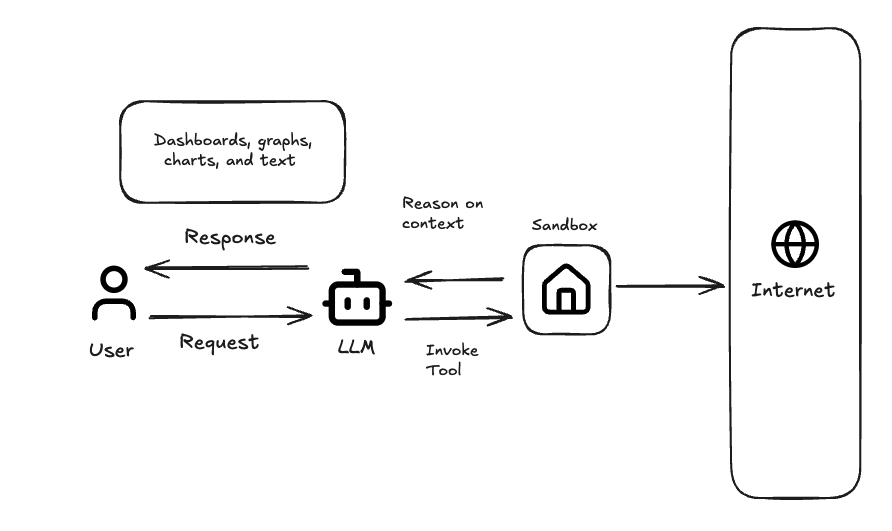
Why do Agents need sandboxes?
Most enterprises have petabytes of data scattered across numerous sources. Commonly this is a warehouse in Snowflake, operational databases in Postgres, customer data in Salesforce, product analytics in Amplitude, and dozens of other SaaS applications accessible only through APIs. For an agent to do non-trivial analytics work, it will require a sandbox in which to dynamically integrate these data sources.
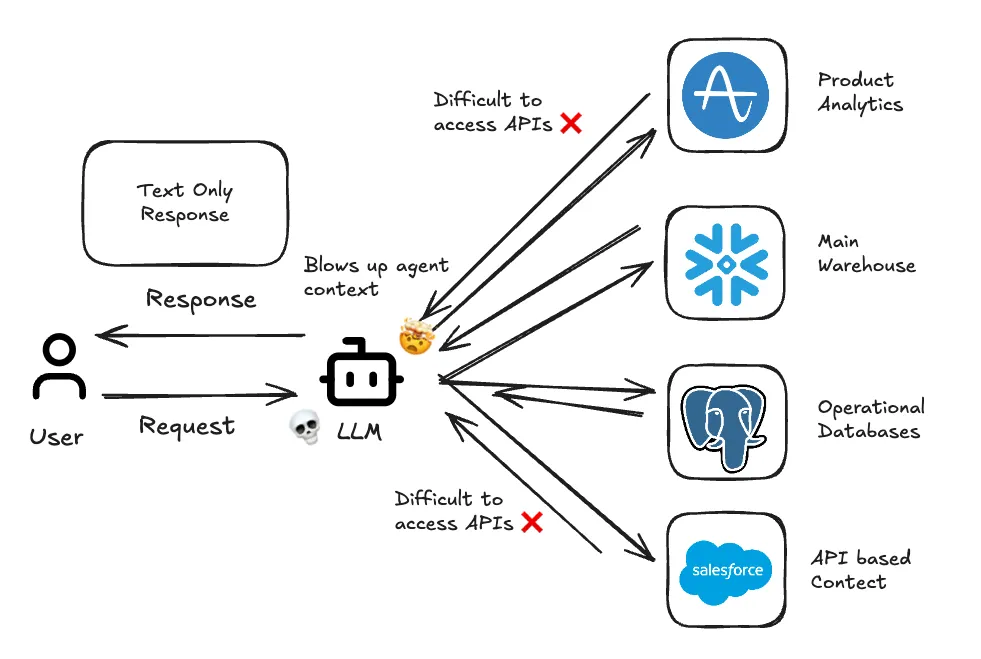
The second, less obvious purpose, is that sandboxes give the agent persistent memory. Persistent memory is important to overcome the stateless nature of large language models. In our scenario above, Snowflake might return 100,000 rows while our API calls return deeply nested JSON that needs preprocessing. Passing this raw data back through the context window for the next reasoning step will hit token limits almost immediately.
Giving the agent the capability to write intermediate results to disk, build up derived datasets and return work-in-progress across multiple reasoning steps lets the agent work the way a human would work. Each step builds on the prior step with an artifact that lives in the sandbox filesystem, not in the prompt.
This is especially important for data work which is inherently iterative. Answers from single systems rarely come in one shot, and with multiple sources of varying syntax and access patterns, iteration is a necessity. Without persistent memory, each iteration requires re-fetching and re-processing everything.
We've found that access to a sandbox radically improves the agent's ability to answer complex data questions.
Introducing the Sandcastle
Sandboxes are a hot topic right now, with new providers emerging regularly. This makes sense. As we've discussed, they're key to extending LLM capabilities in important ways. But general-purpose sandboxes are built for general-purpose workloads. What would a sandbox purpose-built for complex enterprise data analytics look like?
We built it, and we call it the Sandcastle.
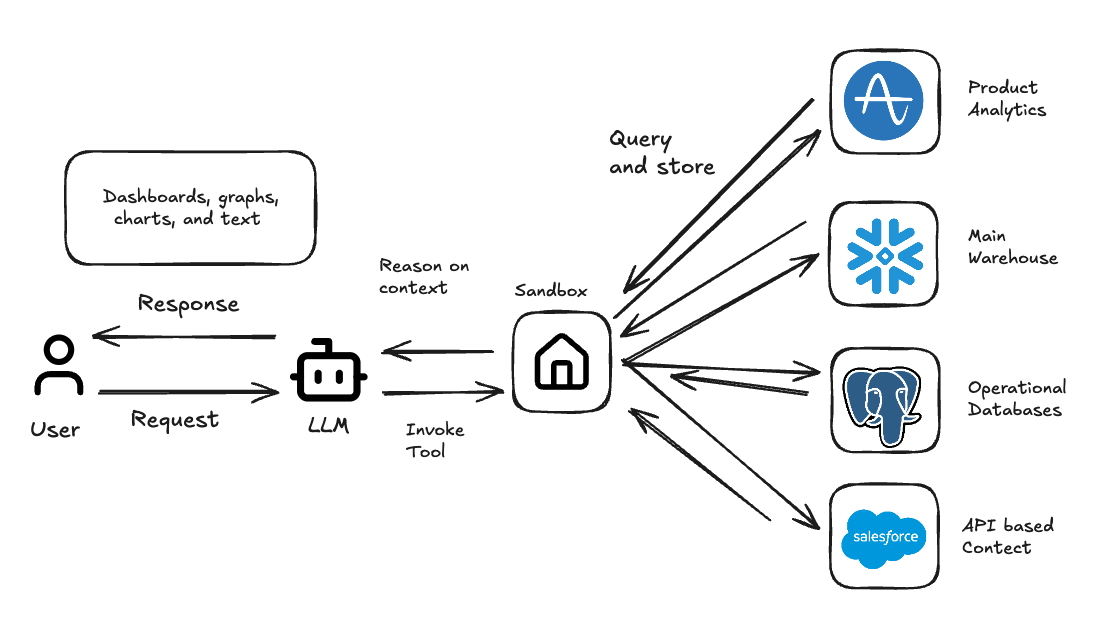
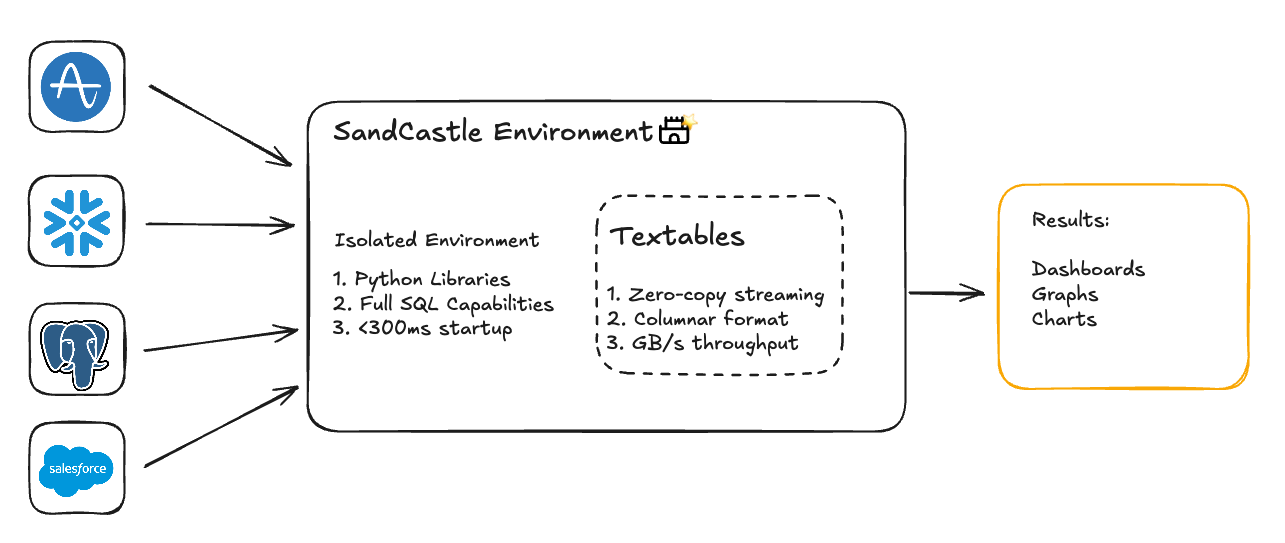
The Sandcastle extends the core ideas of the sandbox: code execution, isolation and persistence with a powerful data management primitive we call the Textable. Where a standard sandbox gives you a place to run code, a Sandcastle gives you a place to run analytics: low-latency access to heterogeneous data sources, fluid conversion between SQL dialects, and enterprise-grade role-based access control baked in from the start.
Textables: a unified interface for data
Over the years, we've built integrations with dozens of data sources including data warehouses like Snowflake and Databricks, BI tools like Tableau and Power BI, relational databases, and flat files from CSVs to Excel. The problem is that each of these speaks a slightly different language and returns data in a slightly different shape. An agent trying to work across all of them would need to context-switch constantly, juggling dialects and formats instead of focusing on the analysis.
Textables abstract this away. They provide a standardized common target format for tabular data regardless of where it originates. The LLM doesn't need to know whether it's talking to Snowflake, Postgres or a CSV that someone uploaded. This also means we can pre-process and join data across sources before the agent ever sees it, making the boundary between data inside and outside the sandbox irrelevant from the agent's perspective.
Critically, Textables are built on Apache Arrow, which allows us to stream data directly into the sandbox using zero-copy transfers at speeds exceeding 10GB/s. When an agent needs to pull a large result set from Snowflake, we're not serializing to JSON and parsing it back out, we're moving columnar data straight into memory. This eliminates the data movement bottleneck that cripples most AI analytics tools when they encounter real enterprise data volumes.
Sandbox + Textables = Sandcastles
Textables provide high-performance, unified data access. Sandboxes provide isolated execution and persistent state. Combined, the Sandcastle enables something that simple text-to-SQL approaches can't touch: real programming against real data at real scale.
This is how TextQL agents are able to join 500GB of historical Snowflake data with live operational data from Postgres, while simultaneously pulling from Salesforce, Amplitude, and whatever other API-based sources your business runs on. We accept the reality that your data lives in isolated silos and we do the heavy lifting so you can make high-conviction, data-driven decisions without building complex ELT pipelines first.
How did we get here?
MVP - Naive Solution
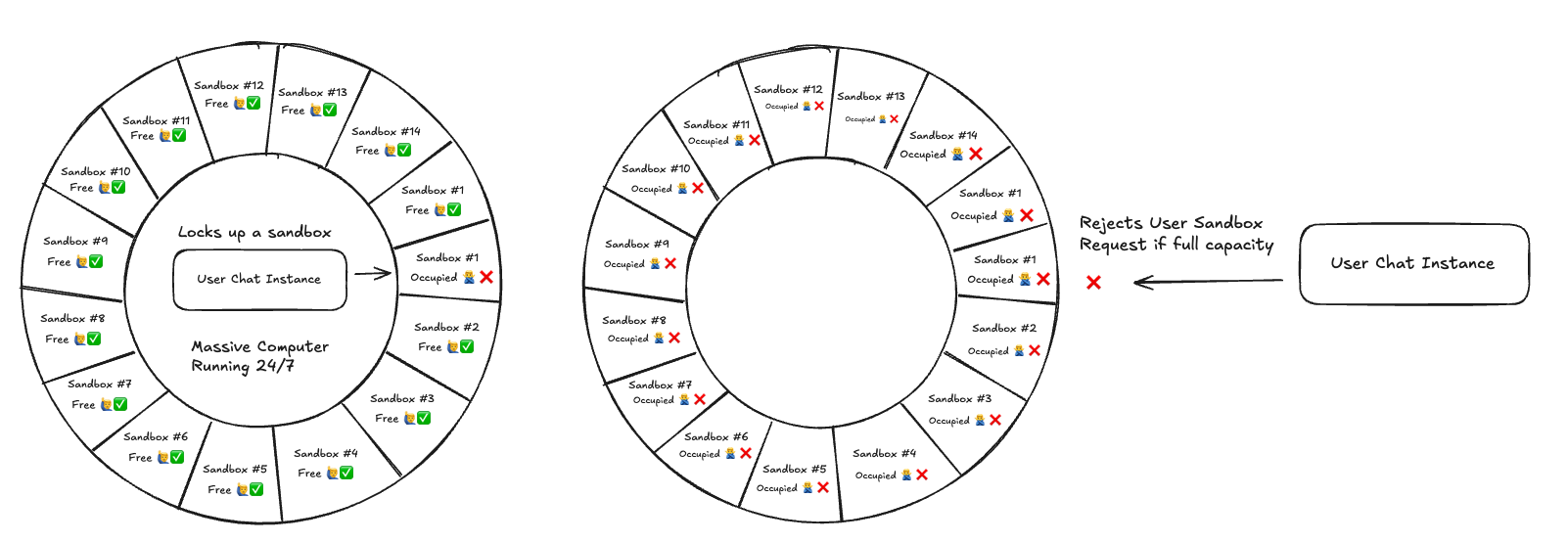
In 2023, we launched the TextQL MVP on ProductHunt. At that time, we had the basic agent architecture that allowed us to query large datasets but we were bottlenecked by infrastructure. In our MVP phase, our sandboxes were hosted on a single computer which had 512gb of ram and 64 cores. We divided that large instance into 64 isolated rotating Docker containers. There were obvious problems with this approach.
- We were paying for a massive compute instance regardless of utilization rate
- We had no way of dynamically resizing the sandboxes depending on workload
- Every update, we had to kill all existing sandboxes
- Hard cap of 64 isolated instances, 65th chat and beyond would be rejected
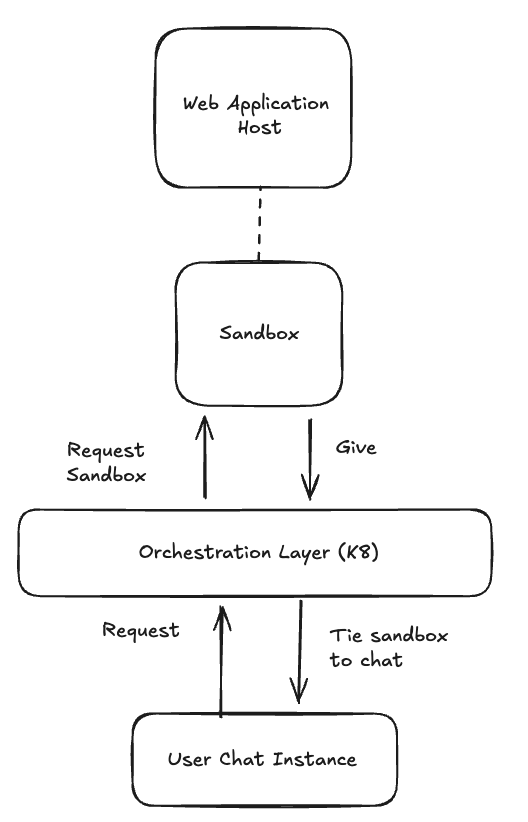
Scaling with K8s (Kubernetes)
As we grew, we quickly realized that our single instance computer was not enough. We decided to migrate our infrastructure to Kubernetes.
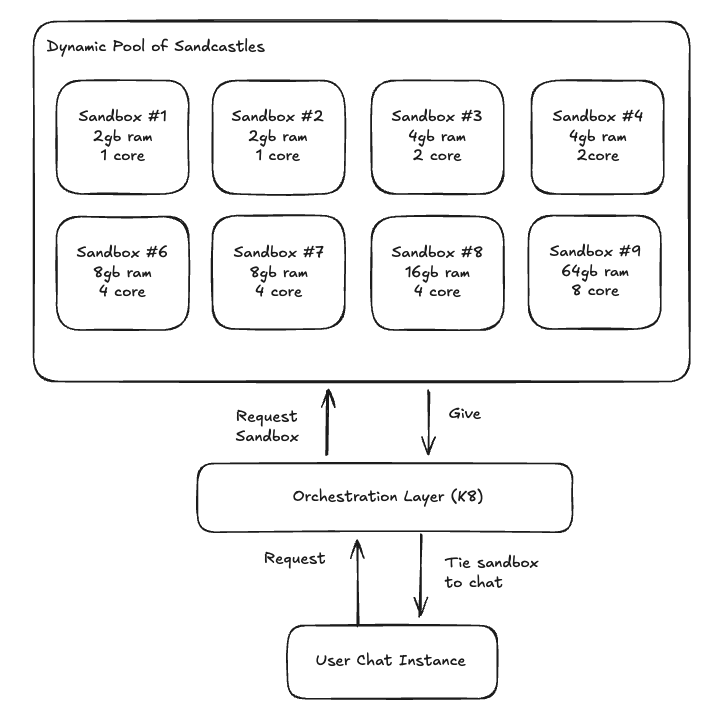
But it paid off, adding this orchestration layer was fundamental in allowing us to be dynamic in resource allocation, to be more fault tolerant, and scale from 10 to 1000+ sandboxes in just 3 minutes.
Additionally we can now:
- Dynamically resize sandboxes from 64mb to 64gb (4x more than the competition), depending on the workload and customer needs
- Spin up new sandboxes in <300ms
- Create sandboxes that leverage multi-core capabilities for heavy analytical needs and running ML models, using gVisor secure kernel.
- Provision resources in response to demand and lower our overall cost to provide the service
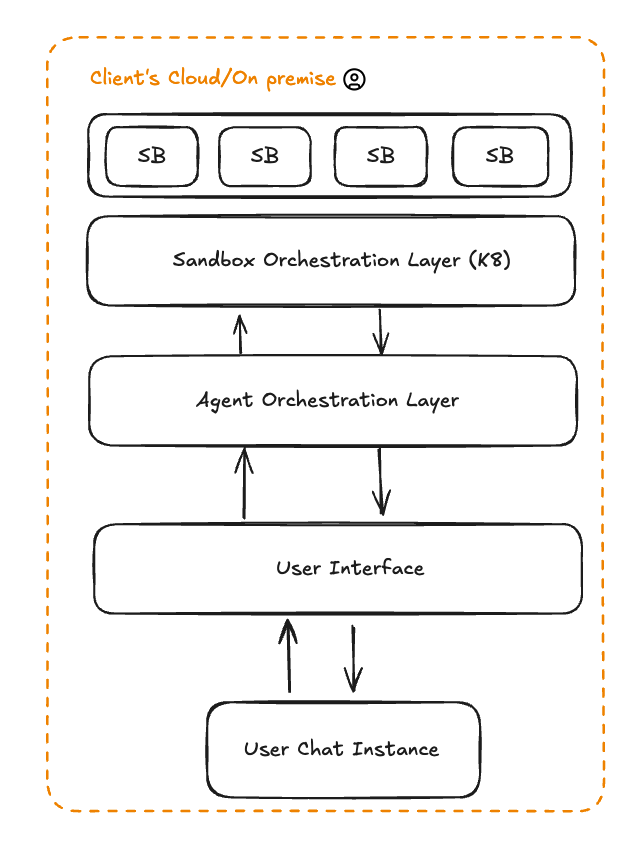
Since we owned the infrastructure layer, the natural next question was: could we run this anywhere? To make that possible, we built our own RBAC (role-based access control), versioning, and authentication system - but designed it to integrate with external OIDC providers.
This gave us deployment flexibility without forcing architectural choices on customers. Use our built-in auth for quick deployments, or integrate with your existing Okta, Azure AD, or custom identity provider. The same Sandcastles configuration runs identically in your VPC, on-prem data centers, or air-gapped networks. For financial services and healthcare customers, this solves a core problem: their data never leaves their perimeter, and access control stays within their existing security infrastructure. As a result of our efforts, all our Fortune 25 clients have on-prem deployments. On-prem deployments account for 50% of all workloads run.
Where are we going next?
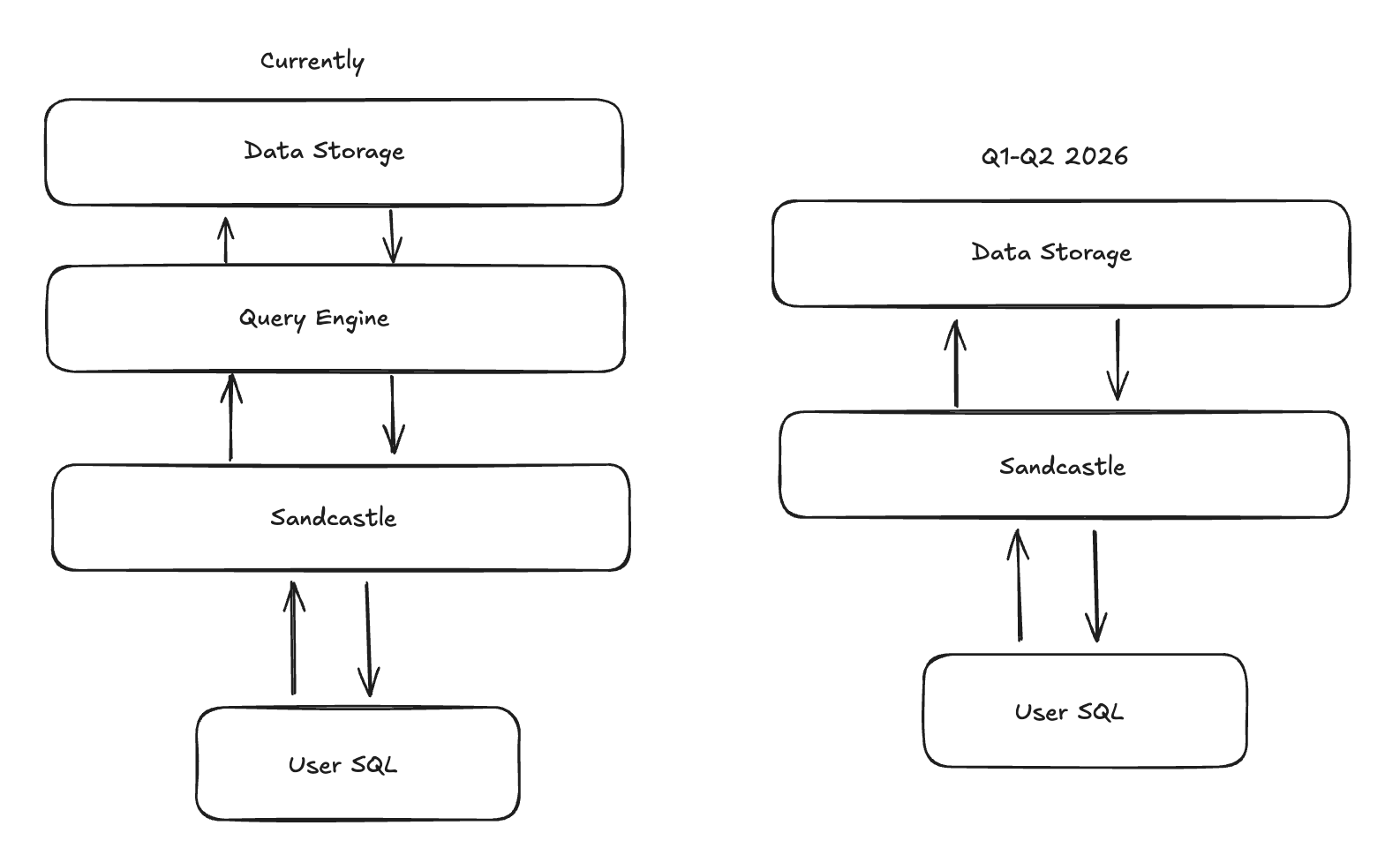
Some questions aren't worth asking until the infrastructure can support the answers. Sandcastles changed what's worth asking. What if compute and storage weren't separate hops? What if a session's output was a living application? What if isolation didn't mean disconnection? We're working on the answers. Today, when an agent queries your warehouse, data travels from source to query engine to sandbox. Each hop costs time. Each hop costs compute. But if the sandbox already holds the data, why does the query engine need to live somewhere else? Collapsing that boundary could eliminate an entire architecture layer. Our early estimates suggest 60% reductions in latency and CPU utilization. The query doesn't travel to the compute. The compute is already there.
Right now, an agent's best work ends when the conversation does. An analyst might build something genuinely useful, a filtered view, a joined dataset, a visualization, only to export it as a static file. But dashboards need to refresh. Filters need to respond. Data needs to stay live. What if the Sandcastle didn't spin down? What if it became the backing server for a persistent application that your whole team could use?
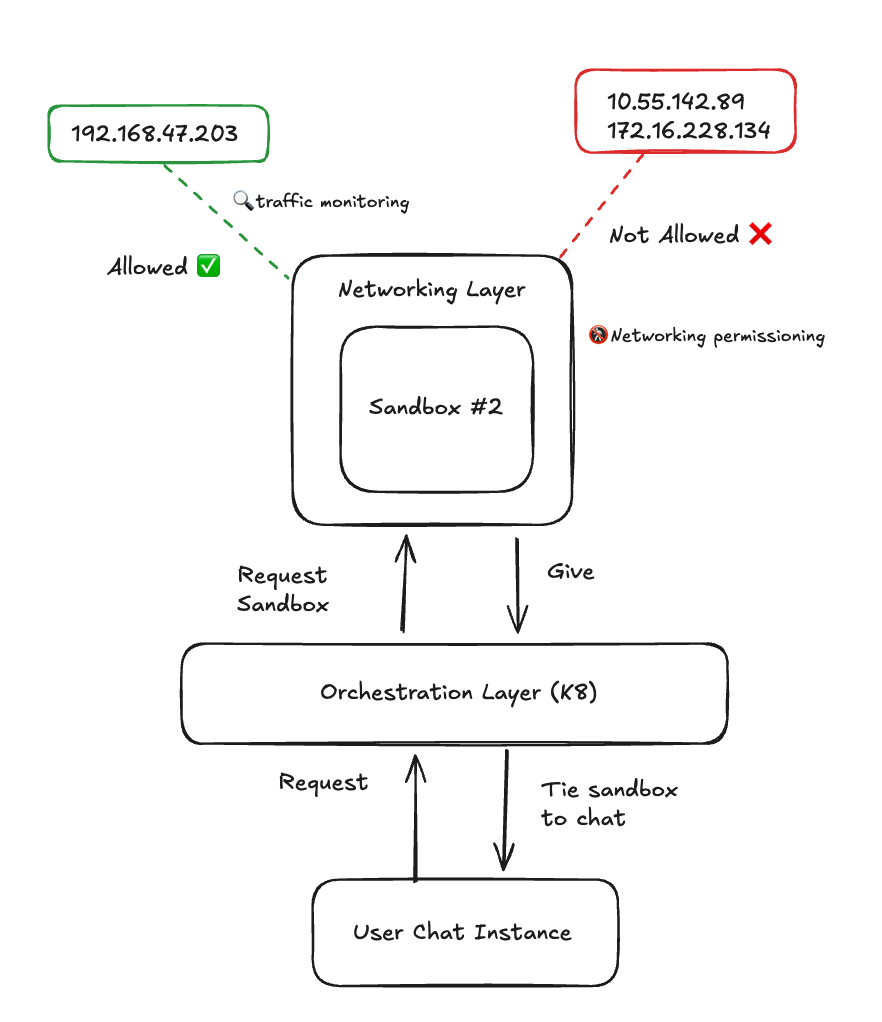
Agents that can't reach the internet are limited. Agents that can reach the internet make security teams nervous. The usual answer is a binary toggle, but that's a crude instrument. An intermediate network layer, one that wraps sandbox traffic with fine-grained permissions and monitoring, would make "isolated" and "connected" less of a tradeoff. Agents could call external APIs. Compliance could sleep at night.
Conclusion
Sandboxes have quickly become critical infrastructure for agents of all kinds. With the explosion in the number of agent workloads running, it follows that some specialization of infrastructure would emerge. Sandcastles, the purpose-built agent infrastructure for complex data workloads, is our answer to this challenge. It's a big reason that interacting with Ana, our data analytics agent, feels so magical.


