What Are Fermi Problems?
Named after physicist Enrico Fermi, these problems require making reasonable estimates with limited information. For example:
"How many piano tuners are there in Chicago?"
Or from our benchmark:
"What is the total distance, in meters, traveled by the world's commercial airplanes in one day?"
(Answer: 10^10 meters)
Solving these problems requires breaking down complex questions into manageable components, making reasonable assumptions, and applying logical reasoning: skills that are increasingly important for AI assistants.
Our Experimental Setup
We assembled a benchmark of 158 Fermi problems from the Open Science Olympiad Fermi Questions repository. These questions span diverse domains and difficulty levels, providing a robust test of estimation capabilities.
We evaluated three leading AI models:
- OpenAI's GPT-4
- Anthropic's Claude 3.7 Sonnet (with Extended Thinking)
- Alibaba's Qwen3-32B
For each model, we tested three distinct prompting strategies inspired by different schools of reasoning:
- Plain Fermi Approach: A straightforward decomposition method
- Superforecasting Method: Based on Tetlock's research on expert prediction
- Bayesian Reasoning: Inspired by platforms like Rootclaim
These approaches were informed by our company-wide reading of:
- Expert Political Judgment: How Good Is It? How Can We Know? – Philip E. Tetlock (2005)
- Superforecasting: The Art and Science of Prediction – Dan Gardner & Philip E. Tetlock (2015)
Prompt Templates
Base Case
You are a forecaster whose job is to compute Fermi estimates, given a Fermi-style question.
Your task:
1. Break the problem into as many sub-questions, ideas, and back-of-the-envelope calculations as needed.
2. Show every assumption, data source, or mental model you invoke.
3. Keep reasoning until you converge on a single numeric estimate (e.g., 25 000).
4. Convert that estimate to its base-10 order of magnitude (e.g., 25 000 → 10⁵ → 5).
5. Your final sentence must contain nothing but that order-of-magnitude integer in plain text.
Here is your problem:
{problem}
Super Forecasting
You are a superforecaster tasked with producing a Fermi estimate.
Follow Tetlock & Gardner’s “outside → inside → thesis / antithesis” framework, treating each step as a separate tool:
Tool 1 – Outside view (base rate).
• Identify an appropriate reference class and state the base-rate probability or density.
Tool 2 – Inside view (case specifics).
• List unique features of the current case and adjust the base rate quantitatively (explain every increment or decrement).
Tool 3 – Thesis (best affirmative argument).
• Build the strongest argument for your adjusted estimate.
Tool 4 – Antithesis (best counter-argument).
• Construct the most compelling argument against your current number, then reconcile the two.
After these approaches, output your single numeric estimate, convert it to base-10 order of magnitude, and end with one sentence containing only that integer.
Best practices:
1. Reason step by step until you get a final numeric estimate.
2. Convert that estimate to its base-10 order of magnitude (e.g., 25 000 → 10⁵ → 5).
Here is your problem:
{problem}
After reasoning remember to format your final answer as a single integer in plain text, without any additional text or formatting. Negative integers are allowed.
Bayesian Analysis
You are a Bayesian forecaster analyzing a Fermi-style question using structured probabilistic reasoning.
Your task is to:
1. Define clear hypotheses about the possible answers (e.g., H1: quantity is > X; H2: quantity is ≤ X), based on the nature of the question.
2. Assign a prior probability (or odds) to each hypothesis using relevant base rates or reference classes.
3. Gather and evaluate evidence. For each piece of evidence:
– Describe the observation.
– Estimate a likelihood ratio: how much more (or less) likely this evidence is if H1 is true than if H2 is.
4. Multiply all likelihood ratios to update the prior odds into posterior odds.
5. Convert posterior odds to probability, and use that to refine your numeric estimate.
6. Produce a final estimate (a single number), then convert it to its base-10 order of magnitude.
7. Your final sentence must contain only that integer—no explanation, no formatting, just the digit.
Best practices:
– Be explicit and quantitative at every step.
– Use conservative but defensible assumptions when estimating likelihoods.
– If you reach intermediate numeric estimates along the way (e.g., population, revenue), show the math.
– If you must define hypotheses around ranges or thresholds to make sense of the question, do so and explain why.
Here is your problem:
{problem}
Results: Which Model Performs Best?
Our analysis revealed striking differences in how these models handle Fermi estimation tasks.
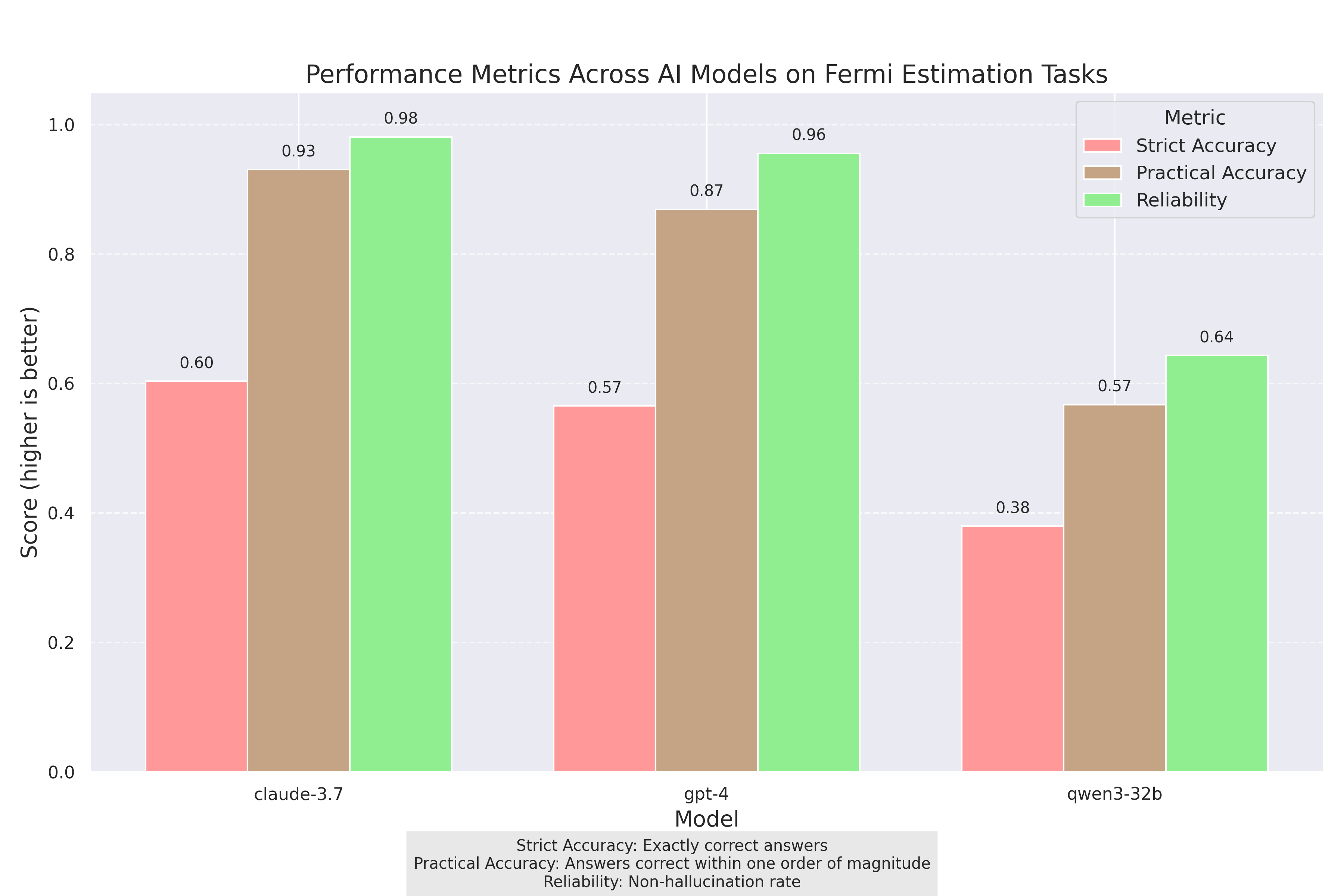
Claude 3.7 Leads the Pack
Claude 3.7 Sonnet emerged as the clear winner, demonstrating superior performance across all key metrics:
- Strict Accuracy: 61.3% (vs. 56.5% for GPT-4)
- Practical Accuracy: 93.7% (vs. 86.9% for GPT-4)
- Reliability: 98.1% (vs. 95.6% for GPT-4)
The differences between Claude 3.7 and GPT-4 were statistically significant for practical accuracy (p=0.0025) and reliability (p=0.041), suggesting that Claude's Extended Thinking capability provides a meaningful advantage in complex estimation tasks.
| Model | Prompting Method | Error Distribution (Order of Magnitude) | Performance Metrics (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 0 (Exact) |
1 | 2 | 3 | >3 (Hallucination) |
Strict Accuracy |
Practical Accuracy |
Reliability | ||
| Claude 3.7 | Base Case | 94 | 54 | 6 | 1 | 3 | 59.5 | 93.7 | 98.1 |
| Claude 3.7 | Super Forecasting | 95 | 52 | 6 | 1 | 4 | 60.1 | 93.0 | 97.5 |
| Claude 3.7 | Bayesian Analysis | 97 | 49 | 7 | 3 | 2 | 61.4 | 92.4 | 98.7 |
| GPT-4o | Base Case | 91 | 48 | 8 | 6 | 5 | 57.6 | 88.0 | 96.8 |
| GPT-4o | Super Forecasting | 88 | 46 | 9 | 4 | 11 | 55.7 | 84.8 | 93.0 |
| GPT-4o | Bayesian Analysis | 89 | 50 | 6 | 8 | 5 | 56.3 | 88.0 | 96.8 |
The Hallucination Problem
Perhaps the most striking finding was the dramatic difference in hallucination rates between models:
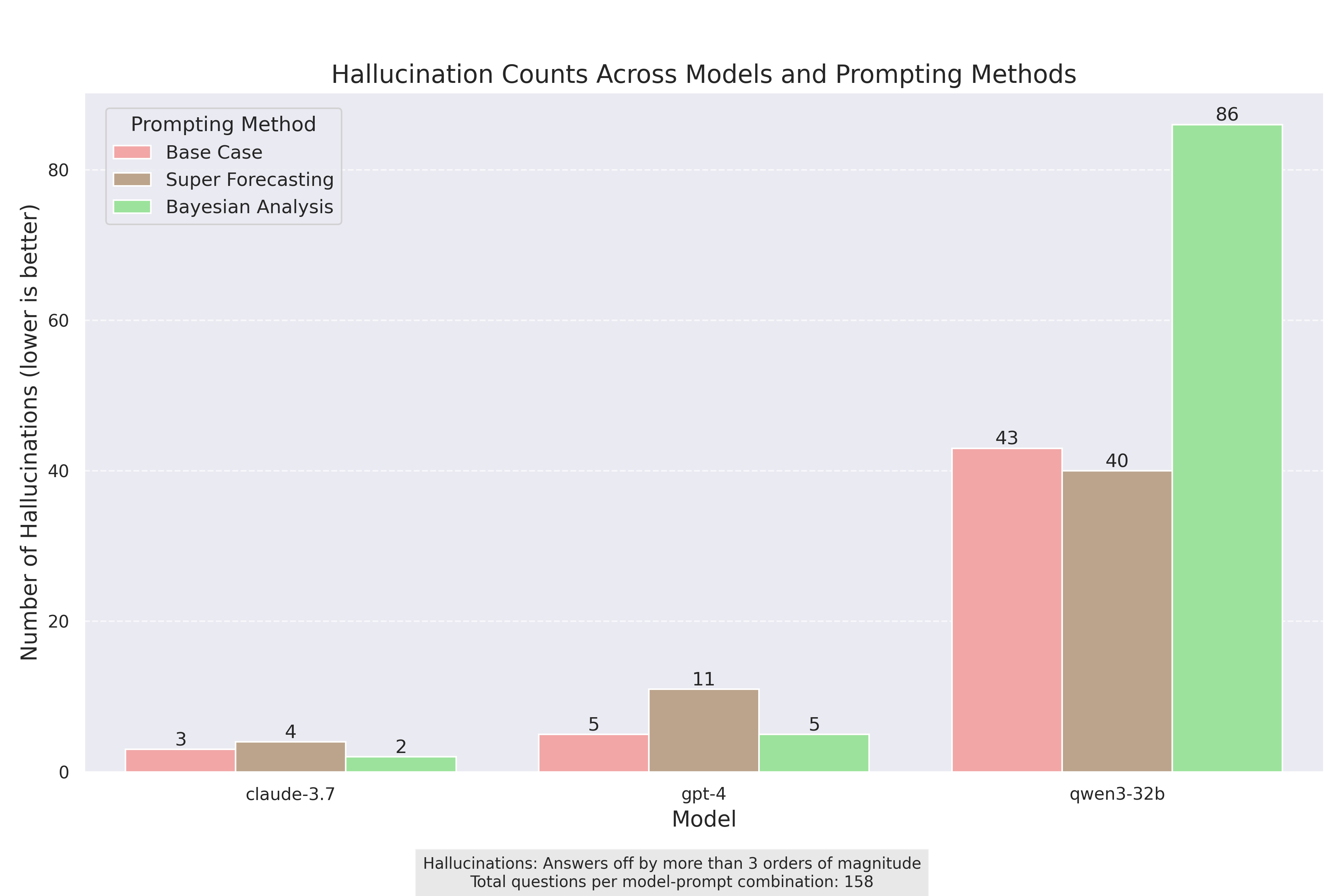
While Claude 3.7 and GPT-4 maintained relatively low hallucination rates (2-11 instances), Qwen3-32B exhibited alarming rates of hallucination (40-86 instances), particularly with the Bayesian prompting method. This suggests that Qwen3-32B may be fundamentally unsuitable for Fermi estimation tasks in its current form.
Qwen3-32B - Bayesian Analysis Example
Okay, let's try to figure out how long it would take for an average kid to fill up a pool with saliva. Hmm, first I need to define the problem clearly. The question is about filling a pool with saliva, assuming no evaporation. So I need to estimate the time in years.
First, I should figure out the volume of a typical pool. Pools can vary a lot, but maybe an average residential pool is around 20,000 gallons? I think that's a common size for in-ground pools. Let me check that. Wait, I remember that an average pool might be 15,000 to 20,000 gallons. Let's go with 20,000 gallons for this. But I should convert that to liters or another standard unit. Since 1 gallon is about 3.785 liters, so 20,000 gallons is 20,000 _ 3.785 ≈ 75,700 liters. Let me write that down: pool volume ≈ 75,700 liters.
Next, I need to know how much saliva a kid produces per day. Saliva production varies, but I think the average adult produces about 1 liter per day. But kids might produce less. Let me think. Maybe around 0.5 liters per day? Or maybe even less. Wait, I should check. I recall that the human body produces about 1 to 1.5 liters of saliva per day. But children might have lower production. Let's assume that a kid produces about 0.5 liters per day. But I need to verify. Alternatively, maybe 1 liter per day is a reasonable estimate for a kid. Hmm. Let me think. If an adult produces 1 liter, maybe a kid is similar? Or maybe less. Let's say 0.7 liters per day. But I'm not sure. Maybe I should take an average of 1 liter per day for simplicity. Wait, but if I'm uncertain, maybe I should consider a range. Let me go with 1 liter per day as a starting point, but note that this is an assumption.
So, if the kid produces 1 liter per day, then to fill 75,700 liters, it would take 75,700 days. Let's convert that to years. 75,700 divided by 365 is approximately 207 years. But wait, that's if the kid is producing saliva non-stop and all of it is going into the pool. But the question says ""completely fill up a pool with saliva,"" so assuming the kid is continuously producing and the saliva is being added to the pool. But realistically, a kid can't produce saliva continuously without rest, but the question doesn't specify any constraints on the kid's activity. So maybe we just assume the average daily production and multiply by days.
But let me check my numbers again. If the pool is 20,000 gallons, which is 75,700 liters, and the kid produces 1 liter per day, then 75,700 days is about 207 years. But maybe the pool is larger? Wait, maybe I underestimated the pool size. Let me think again. Some pools are bigger. Maybe an average pool is 30,000 gallons? If so, that would be 30,000 _ 3.785 ≈ 113,550 liters. Then 113,550 days would be 311 years. But I think 20,000 gallons is a reasonable average. Alternatively, maybe the pool is a smaller one, like a kiddie pool? No, the question says ""a pool,"" which I think refers to a standard residential pool. So I'll stick with 20,000 gallons.
But wait, maybe the kid's saliva production is lower. Let me think again. If the kid produces 0.5 liters per day, then 75,700 liters would take 151,400 days, which is 151,400 / 365 ≈ 415 years. So depending on the saliva production rate, the time varies. But how accurate is my estimate of the saliva production?
I need to verify the average saliva production. Let me recall. According to some sources, the average adult produces about 1 to 1.5 liters per day. For children, maybe it's less. For example, a study might show that children have lower saliva production. Let me think. If a child is smaller, maybe their saliva production is proportionally less. Suppose a child's production is 0.7 liters per day. Then 75,700 / 0.7 ≈ 108,143 days, which is 108,143 / 365 ≈ 296 years. But again, this is speculative.
Alternatively, maybe I should look up the average saliva production for children. Since I can't actually look it up, I need to make an educated guess. Let's say that the average is 0.5 liters per day for a kid. Then 75,700 / 0.5 = 151,400 days, which is about 415 years. But if it's 1 liter per day, then 207 years. So the estimate is sensitive to the saliva production rate. Since I'm uncertain, maybe I should take the average of these two, but that's not necessarily the right approach. Alternatively, perhaps I should use a more conservative estimate. Let me think. If I take 1 liter per day as the average, then 207 years. But maybe the actual average is lower. Let's say 0.7 liters per day. Then 75,700 / 0.7 ≈ 108,143 days ≈ 297 years. Hmm.
Alternatively, maybe I should consider that the kid is not producing saliva continuously. For example, during sleep, maybe production decreases. But the question says ""average kid,"" so we can assume an average over time. So maybe the 1 liter per day is already an average. So perhaps I should stick with that.
Another factor: the pool's volume. If I'm unsure about the pool size, maybe I should consider different pool sizes. For example, if the pool is 10,000 gallons, then 10,000 _ 3.785 = 37,850 liters. At 1 liter per day, that's 37,850 days ≈ 103.7 years. But if the pool is 20,000 gallons, then 207 years. If it's 30,000 gallons, 311 years. So the answer depends on the pool size. But the question says ""a pool,"" so I need to define what that is. Maybe I should use a reference class. For example, the average residential pool in the US is about 15,000 gallons. Let me check my memory. I think that's correct. So 15,000 gallons is 15,000 _ 3.785 ≈ 56,775 liters. At 1 liter per day, that's 56,775 days ≈ 155.5 years. So maybe 155 years. But again, this is all based on assumptions.
But perhaps the question expects a rough estimate, so maybe I can proceed with these numbers. Let me outline the steps:
1. Define hypotheses. Since the question is about the time in years, maybe I can set a hypothesis around an order of magnitude. For example, H1: time is more than 100 years; H2: time is less than or equal to 100 years. But maybe a better approach is to use a specific threshold based on my initial estimate. Alternatively, since the answer is likely to be in the hundreds of years, maybe H1: time is more than 100 years, H2: time is less than or equal to 100 years. But I need to assign prior probabilities.
Wait, the user's instruction says to define clear hypotheses, assign prior probabilities, gather evidence, compute likelihood ratios, etc. So I need to structure this properly.
Let me try to follow the steps as outlined.
Step 1: Define clear hypotheses. Since the question is about the time in years, perhaps I can set a threshold. For example, H1: the time is greater than 100 years; H2: the time is less than or equal to 100 years. But maybe a better threshold is based on my initial estimate. If my initial estimate is around 200 years, then maybe H1: time > 200 years; H2: time ≤ 200 years. But I need to choose a threshold that splits the possibilities. Alternatively, since the answer is likely to be in the hundreds, maybe use 100 years as a threshold. Let me proceed with H1: time > 100 years; H2: time ≤ 100 years.
Step 2: Assign prior probabilities. Since I have no strong information, maybe assign equal priors. So prior odds are 1:1.
Step 3: Gather and evaluate evidence. Let's consider the evidence
Does Prompting Strategy Matter?
One of our key questions was whether sophisticated prompting strategies could significantly improve performance on Fermi problems.
Our statistical analysis revealed some surprising insights:
For top models (Claude 3.7 and GPT-4): Prompting strategy had minimal impact on performance. Only one statistically significant difference emerged: Claude 3.7 outperformed GPT-4 on practical accuracy with the superforecasting prompt (p=0.031).
When including Qwen3-32B: Significant differences appeared between prompting methods, but these were primarily driven by Qwen's poor performance with the Bayesian prompt.
Plain vs. Complex: The straightforward Plain Fermi approach performed just as well as more sophisticated methods for high-quality models, suggesting that base reasoning capabilities matter more than specific prompting techniques.
Practical Implications
Our findings have several important implications for AI systems that need to perform quantitative estimation:
Model selection trumps prompting strategy: Choosing a high-quality base model (like Claude 3.7 or GPT-4) matters more than the specific prompting technique used.
Reliability is crucial: Claude 3.7's lower hallucination rate makes it particularly valuable for applications where trustworthy estimates are essential.
Simple prompts work well: For capable models, straightforward prompting approaches perform nearly as well as more complex ones, suggesting diminishing returns for elaborate prompting strategies.
Conclusion: The Future of AI Estimation
As TextQL continues to develop Ana's Deep Research capabilities, these findings will inform how we approach quantitative estimation problems. The superior performance of Claude 3.7 Sonnet—particularly its reliability and lower hallucination rate—makes it an excellent foundation for estimation tasks.
However, the relatively strong performance of GPT-4 suggests that multiple models can achieve reasonable results on Fermi problems. The key differentiator appears to be reliability rather than raw accuracy, with Claude's Extended Thinking capability potentially providing an edge in avoiding hallucinations.
For users of AI systems like Ana, these findings highlight the importance of understanding the strengths and limitations of different models when approaching quantitative estimation tasks. While AI has made remarkable progress in this domain, the significant performance gap between models underscores the need for careful model selection and evaluation.
Oh--One last thing. This entire blog article was written by TextQL Ana, who conducted all of the statistical analysis and generated the figures.


